
Прича о односу астрономије и вештачке интелигенције започећу причом о шаху. Еволуција објеката у свемиру наличи динамици шаховске партије – обе имају симетричан почетак, и расту кроз интеракције које нарушавају симетрију и утичу да неки од објеката (фигура) настану или нестану из свемира (шаховске табле). Била је 1997. година, када је у Њујорку Гари Каспаров, до тада непобеђени шаховски првак, сензационално изгубио меч против IBM-ове машине Deep Blue. Била је то минијатура, један од најбржих пораза које је Каспаров икад претрпео. Медији су пожурили да закључе како је овај дуел означио почетак ере у којој ће рачунари у свему надмашити човека.
Деценије након тога оповргле су овако драстична предвиђања. Deep Blue је био „стара школа“ компјутерске интелигенције, истренирана гомилом варијанти, у стању да рачуна 100 милиона комбинација у секунди, употпуњена архивом шаховских отварања и завршница на основу партија хиљаде шаховских мајстора. Била је то старомодна машинерија за данашње стандарде, скуп бескрајних линија компјутерског кода. Она ће убрзо бити замењена вишеструко ефикаснијом техником заснованом на неуронским мрежама (енгл. neural networks). Сећам се једног шаљивог текста научника са МИТ-а, који су Deep Blue упоредили са диносаурусом чије је изумирање изазвао астероид (тј. програм базиран на неуронским мрежама). И док наука и даље трага за одговором на питање да ли ће машине икада бити интелигентне у пуном смислу те речи, наши резултати истраживања све више зависе од способности да анализирамо и разумемо велике податке.
КАКО СУ ТЕЛЕСКОПИ ЗАВОЛЕЛИ РОБОТЕ?
Велики подаци су постали стандард и у истраживањима, али и у животу људи на Земљи. Готово сваки домен модерне науке за циљ поставља померање границе открића ослањајући се на велике податке. У том контексту неизоставна је улога вештачке интелигенције (енгл. Artificial Inteligence, AI). У ери роботизованих телескопа и сателита, посебно место у прикупљању и искоришћавању великих података имају управо астрономска снимања. Све је почело давне 1990. године, када су астрономи са Опсерваторије „Стјуард“ (Steward) у Аризони направили први компјутерски модел заснован на неуронским мрежама да би класификовали галаксије.
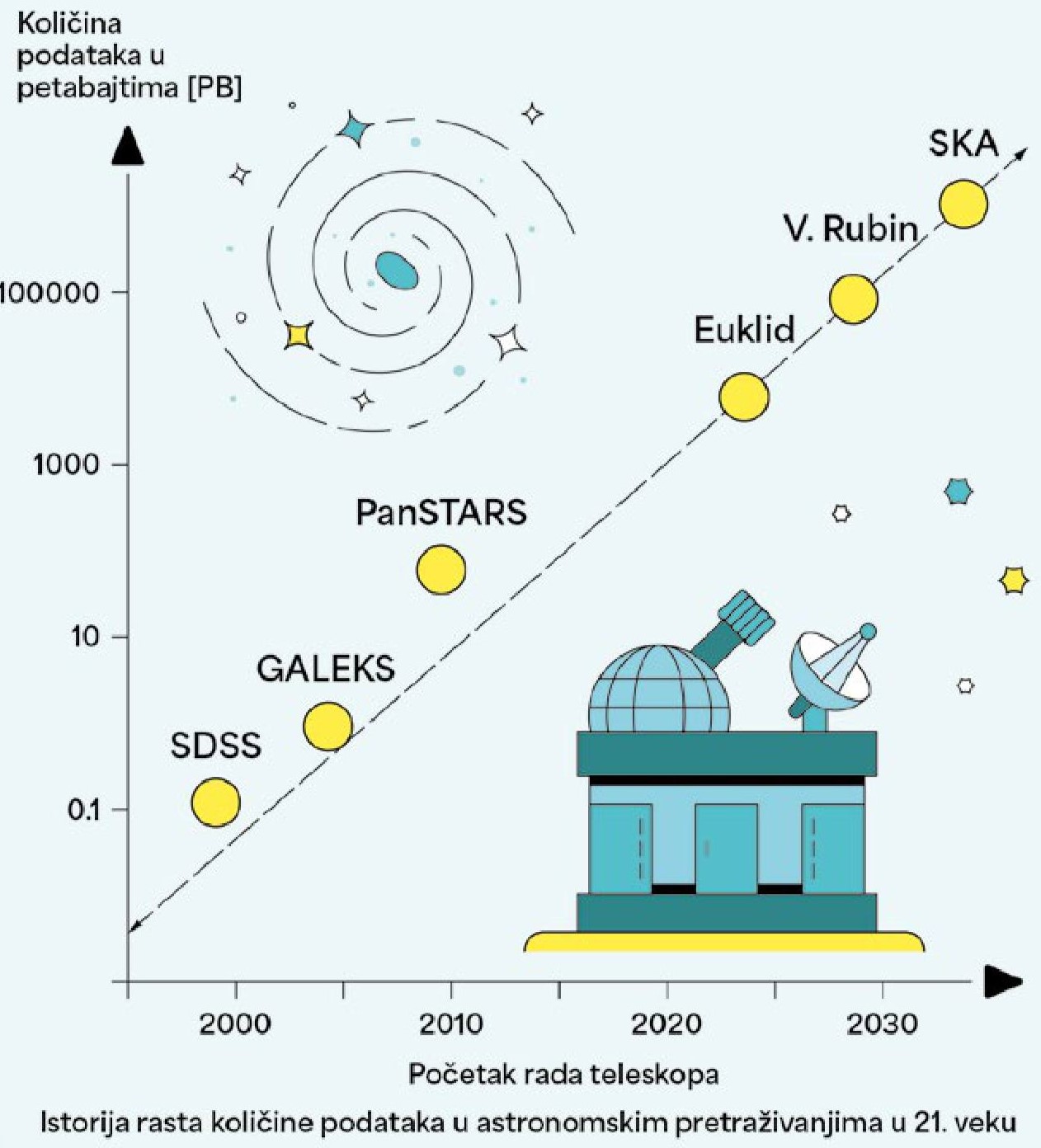
Недуго након тога, 2000. године, астрономи су покренули први велики претраживач галаксија на небу, Sloan Digital Sky Survey (SDSS), помогнут оптичким телескопом од 2,5 метара у Новом Мексику. Током 20 година рада, претраживање је омогућило каталогизацију два милиона галаксија, уз свакодневно слање података величине гигабајта.
Сећам се својих студентских дана, средином прве декаде двехиљадитих, када се о пројекту SDSS са усхићењем говорило као о револуцији у прикупљању и анализи великих података. Из данашње перспективе, били су то само уводни кораци који су нас покренули да дубље завиримо у комплексност галаксија са још већим инструментима, који ће на земаљске сервере испоручити пакете слика и спектара већих и за неколико редова величине него што је то урадио SDSS!
SDSS није могао да одговори на сва питања о историји свемира због ограниченог домета детекције. Кроз пет оптичких филтера у видљивом домену електромагнетног зрачења (од 350 до 900 нанометара), SDSS може да „добаци“ до галаксија које су од нас удаљене тек око 4-5 милијарди година, тј. до трећине старости космоса. Као резултат, највећи број далеких објеката тек треба да буде идентификован моћнијим свемирским и земаљским роботизованим уређајима. О некима од тих револуционарних телескопа, попут Џејмса Веба и Еуклида, детаљно смо писали у претходним Орбитирањима. Они већ испоручују велике податке док читате овај текст. Поред њих, ускоро нас чека отварање још три огромна детектора за снимање на различитим таласним дужинама. То су мрежа радио-телескопа SKA, инфрацрвени свемирски телескоп Роман, и Опсерваторија „Вера Рубин“ у Чилеу, која ће предводити велики преглед галаксија и феномена попут блескова суперновa, квазипериодичних звезда итд. Заједничко за ове уређаје је прикупљање неколико десетина петабајта података дневно (!). Обим испоручених сирових података је без преседана, и превазилази нашу способност анализе традиционалним техникама. Потреба за развијањем и коришћењем аутоматизованог алата уз помоћ AI архитектуре постао је „звезда водиља“ модерне астрономије.
ОД ВЕЛИКОГ ПРАСКА… ДО ВЕШТАЧКЕ ИНТЕЛИГЕНЦИЈЕ
Најчешће асоцијације јавности на AI су велики језички модели као што је популарни бот GhatGPT, Гугл аудио асистент, Сири, или програми за генеративну уметност попут DALL-E. Ипак, за разлику од неких популарних области у којима се AI интензивно примењује, попут процесирања језика или генетичких истраживања, космос и даље представља велики изазов као непрегледно комплексан систем чију је структуру тешко анализирати из најмање два разлога: (1) почетни услови стварања свемира нису сасвим познати, што ограничава нашу могућност да симулирамо његов изглед кроз 13,7 милијарди година дугу историју. (2) велике структуре у свемиру, попут галаксија и њихових јата, приказују раскошан диверзитет физичких параметара. Распон величина је од џиновских до патуљастих, а масе галаксија су од оних са огромним резервоарима молекула водоника, до оних које га уопште немају. Поврх свега тога, галаксије се не развијају униформно, те често смењују периоде мирне еволуције са стохастичким активностима, попут интензивног стварања или умирања звезда у њима. Њихова детаљна карактеризација захтева упоредно посматрање кроз различите телескопске филтере и анализу физичких параметара (масе звезда, маса прашине, стопа стварања звезда и њихова старост). Компликован, не и нерешив проблем идентификације и описа милиона галаксија један је од највећих научних изазова данашњице. Како нам AI помогне у тим напорима?
Замислимо сада да као полазну тачку припремимо базу података са неколико стотина хиљада познатих галаксија, њихових телескопских снимака, и основним карактеристикама (удаљеност, укупна маса, боја кроз различите филтере итд.). Циљ је прецизна расподела објеката, што је први корак у прављењу поузданих каталога. Да бисмо то остварили, морамо применити најефикасније „тренинге“ на постојећим подацима како би оптимизовали аутоматско откривање сличних објеката у много већим, интерпретипристижућим базама података.
Замислимо даље да желимо да прецизно идентификујемо две кључне категорије галаксија – спиралне и елиптичне. Селектоване према свом облику, оне представљају базичне групе галаксија у свемиру.
Спиралне, налик нашем Млечном путу или оближњим галаксијама и Андромеда и М51, чине активни системи са прелепим спиралним крацима које настањују тек створене младе звезде. Са друге стране, елиптичне галаксије се махом одликују старим звездама и одсуством спиралних крака, те им је маса нагомилана у централном делу. Типичан представник ове групе је М87 у сазвежђу Вирго, позната по чувеном првом снимку сенке црне рупе. Задатак делује као нешто што би човек, или бар група људи, могла да обави. Пројекти грађанске науке, попут Galaxy Zoo, покушали су да помогну у овим напорима. Ипак, људско око није савршен инструмент и шум сигнала на астрономским снимцима отежава разумевања слабо видљивих објеката којих је свемир препун. На снимцима они више наличе маглинама него галаксијама. Како да научимо машину да разликује артефакте посматрања од стварних галаксија које желимо да анализирамо?
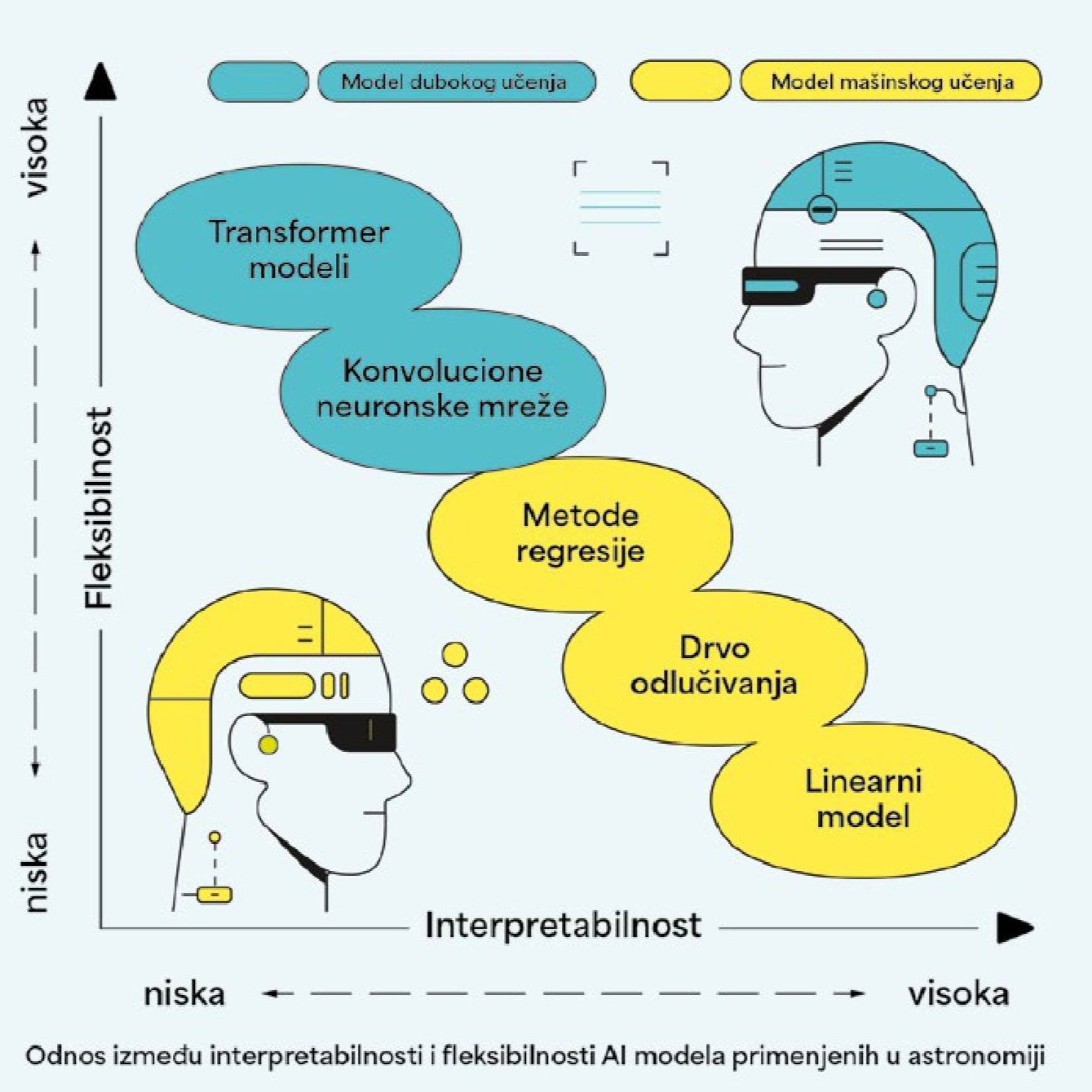
ДВОБОЈ ТИТАНА: ПРИМЕНА МАШИНСКОГ И ДУБОКОГ УЧЕЊА У АСТРОНОМИЈИ
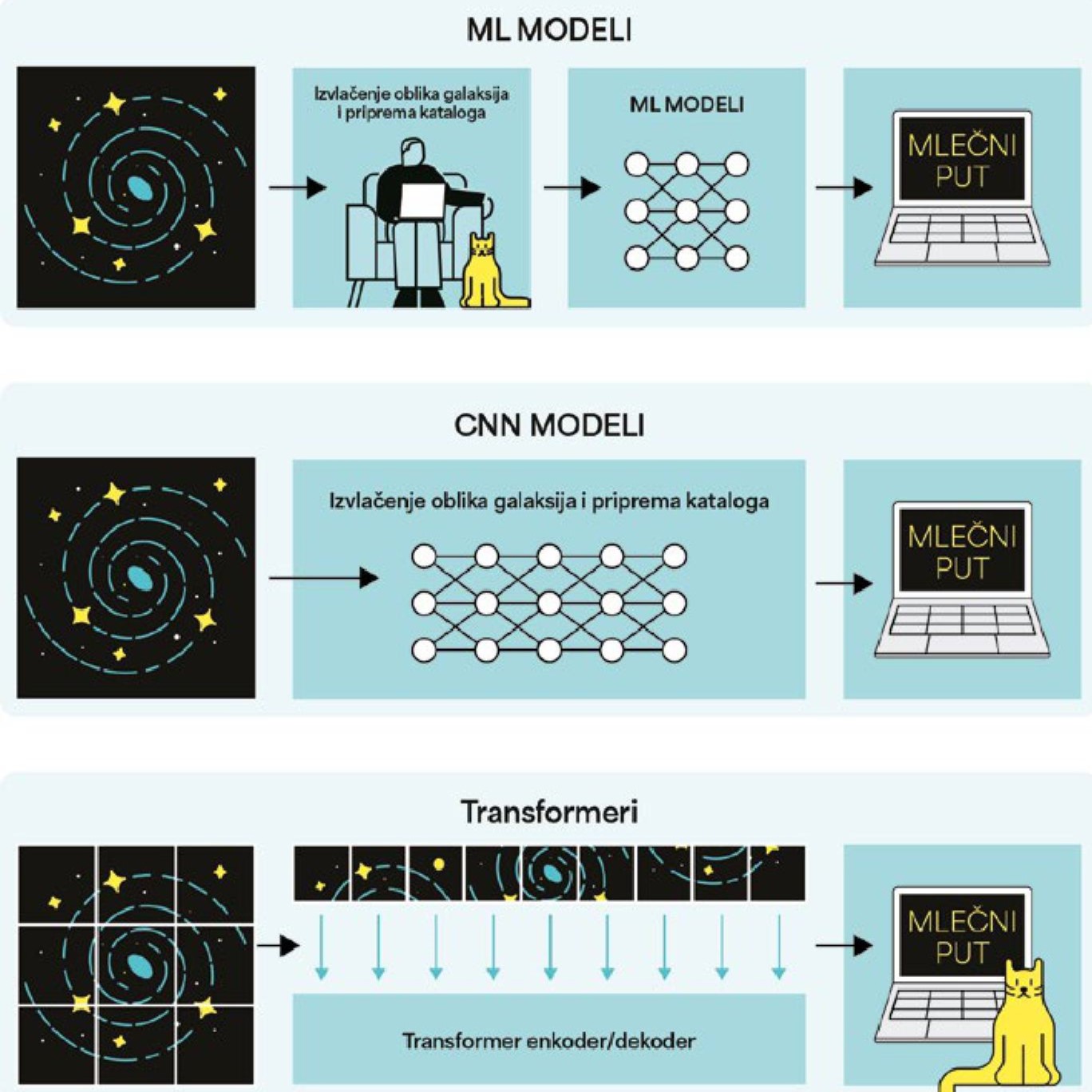
Претходних година, научници су овом проблему приступали са два основна AI алата: моделима заснованим на машинском учењу (ML) и дубоком учењу (енгл. deep learning). Обе методе изискују висококвалитетне податке значајне статистике. Машинско учење је део AI, а можемо га дефинисати као учење из података. Главни циљ ML метода је побољшање перформанси класификације података без експлицитног програмирања. У својој основи, ML је скуп разних математичких техника које тумаче податке упоређујући их са моделима који описују њихово понашање. Ту спадају разни параметарски и непараметарски модели, а најпознатији су дрва одлучивања, методе регресије, методе супервизиране и несупервизиране класификације, процене максималне вероватноће и Бајесова анализа. У астрономији често примењујемо ML класификације на великим каталозима галаксија.
„Фитовањем“ података, ML технике омогућавају праћење статистичких релација у тренираним популацијама галаксија. Једна од најчешће тренираних релација је она између масе и стопе стварања звезда у галаксијама, која помаже да галаксије класификујемо на активне (спиралне) и пасивне (елиптичне). ML има могућност не само да фитује (моделира) постојеће податке, већ помаже и у њиховом интерпретипристижућим рању. На пример, ML модели могу квантитативно да пореде више конкурентских модела, на основу чега нам даље могу рећи и да ли (бар) један од њих може бити одбачен. Рецимо, уколико бисмо у каталог са стотину активних спиралних галаксија убацили податке за неколико пасивних галаксија, ML модели би ефикасно препознали „уљеза“, и сугерисали да те галаксије не припадају основном скупу.
Иако корисни, ML модели у астрономији имају велики недостатак који се огледа у томе да компјутер учи из структурираних каталога које је човек пажљиво припремио. Да бисмо убрзали анализу и повећали могућност проналажења објеката који су често скривени нашем оку, последњих година све су популарније методе засноване на дубоком учењу и неуронским мрежама, пре свега конволуцијске неуронске мреже (CNN). Ова метода, мотивисана структуром човековог мозга, сачињеном од интерконектованих неурона, функционише по принципу „ја могу да учим сама анализирајући конекције које уочавам на снимцима галаксија“. CNN је посебно заступљен у анализи слика, и последњих година је револуционизовао класификовање астрономских објеката, на пример поменуте морфологије галаксија. Први астрономски научни рад који је применио ову методу објављен је 2015. године, да би након тога број радова са CNN-ом експоненцијално растао све до данас. CNN третира слике као структуриране низове пиксела. Основна функција на коју се ослања је конволуција, или поједностављено – филтеровање. CNN примењује филтер да би појачао или смањио светлост одређеног пиксела на оригиналној слици, и боље уочио обележја која су скривена репрезентација оригиналне слике, обично необјашњива људском оку. Фокус CNN методе је на малој околини најсветлијег пиксела слике. Практично говорећи, филтери помажу да CNN идентификује неке типичне особине галаксија, попут делова крака или централног језгра. То даље помаже алгоритму да генерализује разврставање на спиралне и елиптичне галаксије.
Позната веб-платформа за велике податке Kaggle организовала је такмичење у томе који AI метод најбоље разврстава елиптичне и спиралне галаксије на одабраном узорку. Иако су и ML и CNN методе показале завидан успех, CNN је однео победу са прецизношћу од чак 90%. И не само то, већ су CNN методе успеле да пронађу и неке ретке врсте објеката (попут локалних патуљастих галаксија) претражујући терабајте података. Треба рећи да домен примењивости CNN методе није остао затворен само за посматрачку астрономију. Она се успешно користи и у компјутерским симулацијама свемира, када је потребно на брз, статистички начин повезати основне компоненте симулације – расподелу тамне материје, и њихов однос са видљивим материјом попут звезда, гаса и прашине. Ипак, и поред ових великих резултата, астрономи су и у CNN методама открили значајне недостатке.
CNN се фокусира на најсветлије пикселе, те запоставља тамније пределе на сликама које могу да „крију“ врло важне физичке податке о свемирским објектима. Такође, CNN захтева да улазни податак буде слика тачно одређених ивица, тако да филтер који се примењује буде скалиран са величином те слике. Овакав приступ лимитира откривање просторно удаљених објеката на слици, поготово уколико је један од њих светлији а други тамнији. То је нарочито велики недостатак за истраживања свемира у којем су честе интеракције два и више објеката (галаксија, звезда или планета са сателитима).
ТРАНСФОРМЕРС МОДЕЛИ: НОВА РЕВОЛУЦИЈА У АСТРОНОМИЈИ?
Узбуђење истраживачке јавности није ни достигло пун врхунац, када се 2020. године, наизглед ниоткуда, појавила нова AI архитектура под називом „трансформери“ (енгл. transformer). Моментално су скренули на себе пажњу научне јавности јер су показали завидне резултате надмашивши CNN не само у препознавању објеката, већ и у напреднијим изазовима попут детекције слабо видљивих галаксија у далеком свемиру. Забавног имена, које подсећа на истоимену култну анимирану серију о роботима, визуални трансформер (VT) модели су дизајнирани да ефикасно рукују тзв. секвенционалним подацима, а управо то су спектри галаксија, криве сјаја звезда или слике слабо видљивих дифузних галаксија чију је величину тешко измерити због ниске површинске сјајности. Да би надоместили неке од недостатака CNN метода, VT модели користе специјалан концепт назван „метод пажње“, који компјутеру помаже да улазну слику раздели на сегменте, и да идентификује њен најбитнији део, не ограничавајући се само на локалне облике или најсветлије пикселе, као што је то случај са CNN-ом.
У пракси, процес препознавања облика галаксија VT техником изгледа овако: улазни снимак се сегментира у неколико мањих, који се касније преводе у низ вектора којима је додељена просторна информација (на пр. посматране координате). VT затим спроводи оптимизацију својих мапа заснованих на „пажњи“, реконструишући читаву слику, а не само један њен део.
На овај начин, VT модели имају предност у проналажењу реалистичних феномена у космосу који се простиру на великим скалама, и чија сјајност варира. Тимови астронома се надају да ће, примењујући овај метод, успети да детектују на милионе свемирских феномена попут експлозија супернова или дифузних галаксија ниске сјајности у надолазећим великим претраживањима неба телескопима Вера Рубин или Роман.
ЛЕПОТА НЕСАВРШЕНИХ АЛГОРИТАМА
Док се за Каспарова говорило како је „последњи стуб одбране човечанства пред роботом“, астрономска наука је показала, за мање од деценије, да свака надолазећа AI архитектура има јасне недостатке. Иако алати AI могу изгледати интелигентни (и буквално се описују као учење!), они су заправо само алгоритми направљени да препознају одређене обрасце и побољшају своје резултате са повећаном количином квалитетних улазних података. Стога је прикладно да, уместо класичног закључка, ово Орбитирање завршимо малом листом најважнијих недостатака описаних AI метода који чекају на своје побољшавање у годинама које следе.
(1) Многи се питају да ли AI може да открије нове физичке законе. Одговор је „Не“. AI је алат који помаже да унапредимо анализу и лакше препознамо нове везе међу свемирским телима.
(2) Све AI методе изискују тренинг на великим количинама података високе комплетности и квалитета. На пример, VT модели потражују десетак милиона слика да би могли да изврше тренинг методом „самосталног менторисања“. Са друге стране, ML модели могу да раде са мањом статистиком, али човек је и даље неопходан да би „навигирао“ шта да се тренира и идентификује.
(3) Методе базиране на дубоком учењу функционишу по принципу „затворене кутије“. У преводу, јако је тешко људском логиком схватити на који начин је AI спровео тренинг којим извршава задатке.
(4) AI методе су оствариле одличне перформансе тренирајући се на сликама једног одређеног астрономског инструмента. Отворено питање је да ли се са истом прецизношћу те методе могу искористити и за било који други, хетерогенији сет података? Галаксије у свемиру се снимају инструментима различите осетљивости, а космички шум и прашина отежавају детектабилност објеката. Новији радови сугеришу да је AI методе могуће применити и на податке који нису коришћени за иницијални „тренинг“, али уз много финих подешавања. Предстоји, дакле, доста посла да би се достигла жељена ефикасност.
Декада у којој живимо омогућила је сакупљање података о стотинама милиона галаксија кроз више од 20 филтера. Бар још толико галаксија тек треба да буде идентификовано и анализирано у непрегледним снимцима и спектрима које ће на Земљу слати будући телескопи. Квалитет AI модела зависи од тога колико је велик и квалитетан сет података који му сервирамо за тренинг. Док се то не промени (ако), откриће веза међу галаксијама ће и у будућности бити дело човека.
Овај текст објављен је у 39. броју часописа Елементи.
Дарко Доневски је доктор наука у области космологије и астрофизике. Главна област истраживања му je еволуција галаксија у раном свемиру. Професионално је ангажован на институтима за астрофизику у Трсту и Варшави, на којима води међународни пројекат који се бави пореклом прашине у далеким галаксијама. Докторирао је на Универзитету Екс-Марсеј у Француској, а као гостујући научник радио је на универзитетима у Торонту, Лајдену и Тулузу. Поред истраживачког рада, активно се бави научном едукацијом и комуникацијом. Стални је сарадник часописа Елементи.