
Priča o odnosu astronomije i veštačke inteligencije započeću pričom o šahu. Evolucija objekata u svemiru naliči dinamici šahovske partije – obe imaju simetričan početak, i rastu kroz interakcije koje narušavaju simetriju i utiču da neki od objekata (figura) nastanu ili nestanu iz svemira (šahovske table). Bila je 1997. godina, kada je u Njujorku Gari Kasparov, do tada nepobeđeni šahovski prvak, senzacionalno izgubio meč protiv IBM-ove mašine Deep Blue. Bila je to minijatura, jedan od najbržih poraza koje je Kasparov ikad pretrpeo. Mediji su požurili da zaključe kako je ovaj duel označio početak ere u kojoj će računari u svemu nadmašiti čoveka.
Decenije nakon toga opovrgle su ovako drastična predviđanja. Deep Blue je bio „stara škola“ kompjuterske inteligencije, istrenirana gomilom varijanti, u stanju da računa 100 miliona kombinacija u sekundi, upotpunjena arhivom šahovskih otvaranja i završnica na osnovu partija hiljade šahovskih majstora. Bila je to staromodna mašinerija za današnje standarde, skup beskrajnih linija kompjuterskog koda. Ona će ubrzo biti zamenjena višestruko efikasnijom tehnikom zasnovanom na neuronskim mrežama (engl. neural networks). Sećam se jednog šaljivog teksta naučnika sa MIT-a, koji su Deep Blue uporedili sa dinosaurusom čije je izumiranje izazvao asteroid (tj. program baziran na neuronskim mrežama). I dok nauka i dalje traga za odgovorom na pitanje da li će mašine ikada biti inteligentne u punom smislu te reči, naši rezultati istraživanja sve više zavise od sposobnosti da analiziramo i razumemo velike podatke.
KAKO SU TELESKOPI ZAVOLELI ROBOTE?
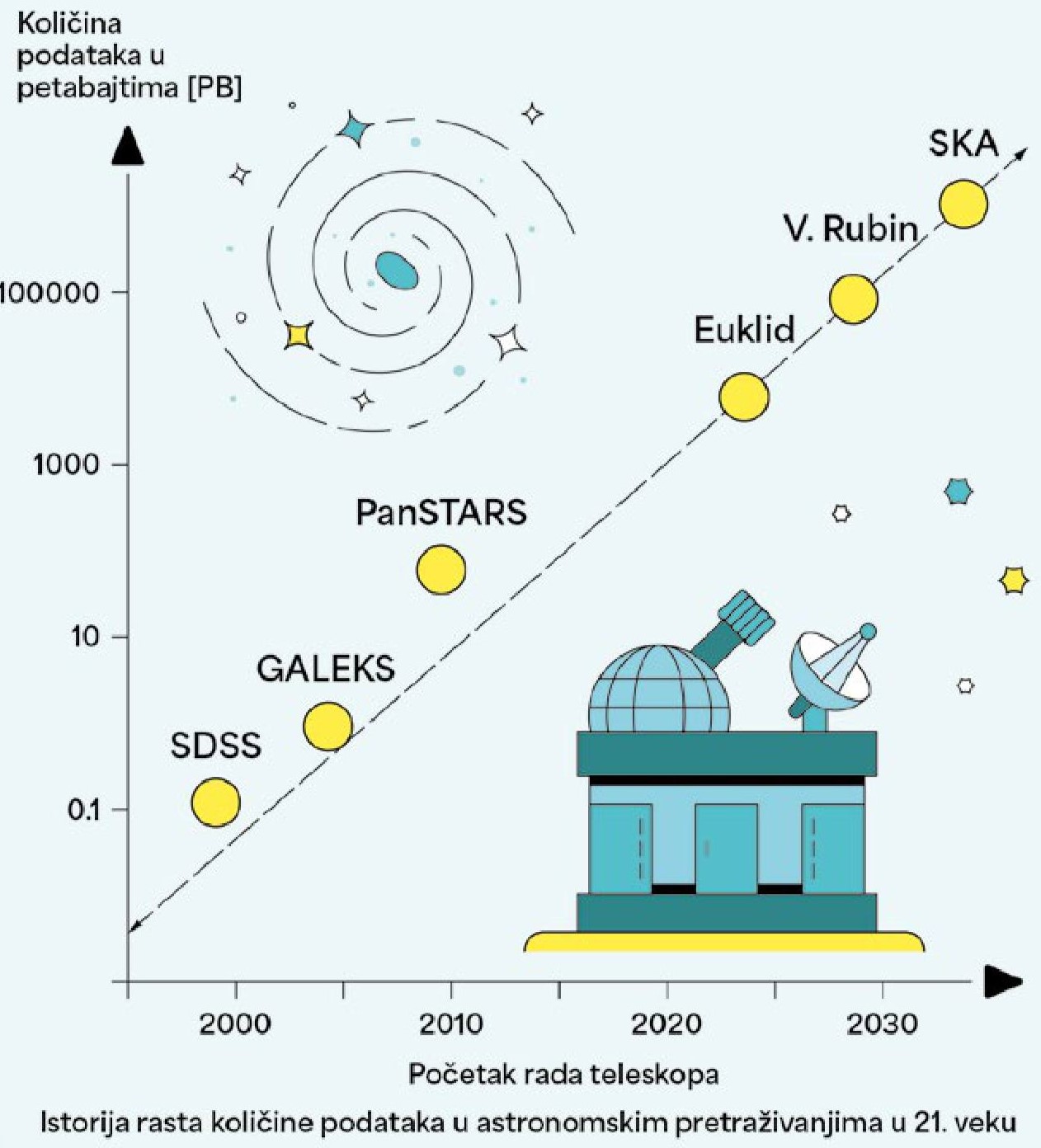
Veliki podaci su postali standard i u istraživanjima, ali i u životu ljudi na Zemlji. Gotovo svaki domen moderne nauke za cilj postavlja pomeranje granice otkrića oslanjajući se na velike podatke. U tom kontekstu neizostavna je uloga veštačke inteligencije (engl. Artificial Inteligence, AI). U eri robotizovanih teleskopa i satelita, posebno mesto u prikupljanju i iskorišćavanju velikih podataka imaju upravo astronomska snimanja. Sve je počelo davne 1990. godine, kada su astronomi sa Opservatorije „Stjuard“ (Steward) u Arizoni napravili prvi kompjuterski model zasnovan na neuronskim mrežama da bi klasifikovali galaksije.
Nedugo nakon toga, 2000. godine, astronomi su pokrenuli prvi veliki pretraživač galaksija na nebu, Sloan Digital Sky Survey (SDSS), pomognut optičkim teleskopom od 2,5 metara u Novom Meksiku. Tokom 20 godina rada, pretraživanje je omogućilo katalogizaciju dva miliona galaksija, uz svakodnevno slanje podataka veličine gigabajta.
Sećam se svojih studentskih dana, sredinom prve dekade dvehiljaditih, kada se o projektu SDSS sa ushićenjem govorilo kao o revoluciji u prikupljanju i analizi velikih podataka. Iz današnje perspektive, bili su to samo uvodni koraci koji su nas pokrenuli da dublje zavirimo u kompleksnost galaksija sa još većim instrumentima, koji će na zemaljske servere isporučiti pakete slika i spektara većih i za nekoliko redova veličine nego što je to uradio SDSS!
SDSS nije mogao da odgovori na sva pitanja o istoriji svemira zbog ograničenog dometa detekcije. Kroz pet optičkih filtera u vidljivom domenu elektromagnetnog zračenja (od 350 do 900 nanometara), SDSS može da „dobaci“ do galaksija koje su od nas udaljene tek oko 4-5 milijardi godina, tj. do trećine starosti kosmosa. Kao rezultat, najveći broj dalekih objekata tek treba da bude identifikovan moćnijim svemirskim i zemaljskim robotizovanim uređajima. O nekima od tih revolucionarnih teleskopa, poput Džejmsa Veba i Euklida, detaljno smo pisali u prethodnim Orbitiranjima. Oni već isporučuju velike podatke dok čitate ovaj tekst. Pored njih, uskoro nas čeka otvaranje još tri ogromna detektora za snimanje na različitim talasnim dužinama. To su mreža radio-teleskopa SKA, infracrveni svemirski teleskop Roman, i Opservatorija „Vera Rubin“ u Čileu, koja će predvoditi veliki pregled galaksija i fenomena poput bleskova supernova, kvaziperiodičnih zvezda itd. Zajedničko za ove uređaje je prikupljanje nekoliko desetina petabajta podataka dnevno (!). Obim isporučenih sirovih podataka je bez presedana, i prevazilazi našu sposobnost analize tradicionalnim tehnikama. Potreba za razvijanjem i korišćenjem automatizovanog alata uz pomoć AI arhitekture postao je „zvezda vodilja“ moderne astronomije.
OD VELIKOG PRASKA… DO VEŠTAČKE INTELIGENCIJE
Najčešće asocijacije javnosti na AI su veliki jezički modeli kao što je popularni bot GhatGPT, Gugl audio asistent, Siri, ili programi za generativnu umetnost poput DALL-E. Ipak, za razliku od nekih popularnih oblasti u kojima se AI intenzivno primenjuje, poput procesiranja jezika ili genetičkih istraživanja, kosmos i dalje predstavlja veliki izazov kao nepregledno kompleksan sistem čiju je strukturu teško analizirati iz najmanje dva razloga: (1) početni uslovi stvaranja svemira nisu sasvim poznati, što ograničava našu mogućnost da simuliramo njegov izgled kroz 13,7 milijardi godina dugu istoriju. (2) velike strukture u svemiru, poput galaksija i njihovih jata, prikazuju raskošan diverzitet fizičkih parametara. Raspon veličina je od džinovskih do patuljastih, a mase galaksija su od onih sa ogromnim rezervoarima molekula vodonika, do onih koje ga uopšte nemaju. Povrh svega toga, galaksije se ne razvijaju uniformno, te često smenjuju periode mirne evolucije sa stohastičkim aktivnostima, poput intenzivnog stvaranja ili umiranja zvezda u njima. Njihova detaljna karakterizacija zahteva uporedno posmatranje kroz različite teleskopske filtere i analizu fizičkih parametara (mase zvezda, masa prašine, stopa stvaranja zvezda i njihova starost). Komplikovan, ne i nerešiv problem identifikacije i opisa miliona galaksija jedan je od najvećih naučnih izazova današnjice. Kako nam AI pomogne u tim naporima?
Zamislimo sada da kao polaznu tačku pripremimo bazu podataka sa nekoliko stotina hiljada poznatih galaksija, njihovih teleskopskih snimaka, i osnovnim karakteristikama (udaljenost, ukupna masa, boja kroz različite filtere itd.). Cilj je precizna raspodela objekata, što je prvi korak u pravljenju pouzdanih kataloga. Da bismo to ostvarili, moramo primeniti najefikasnije „treninge“ na postojećim podacima kako bi optimizovali automatsko otkrivanje sličnih objekata u mnogo većim, interpretipristižućim bazama podataka.
Zamislimo dalje da želimo da precizno identifikujemo dve ključne kategorije galaksija – spiralne i eliptične. Selektovane prema svom obliku, one predstavljaju bazične grupe galaksija u svemiru.
Spiralne, nalik našem Mlečnom putu ili obližnjim galaksijama i Andromeda i M51, čine aktivni sistemi sa prelepim spiralnim kracima koje nastanjuju tek stvorene mlade zvezde. Sa druge strane, eliptične galaksije se mahom odlikuju starim zvezdama i odsustvom spiralnih kraka, te im je masa nagomilana u centralnom delu. Tipičan predstavnik ove grupe je M87 u sazvežđu Virgo, poznata po čuvenom prvom snimku senke crne rupe. Zadatak deluje kao nešto što bi čovek, ili bar grupa ljudi, mogla da obavi. Projekti građanske nauke, poput Galaxy Zoo, pokušali su da pomognu u ovim naporima. Ipak, ljudsko oko nije savršen instrument i šum signala na astronomskim snimcima otežava razumevanja slabo vidljivih objekata kojih je svemir prepun. Na snimcima oni više naliče maglinama nego galaksijama. Kako da naučimo mašinu da razlikuje artefakte posmatranja od stvarnih galaksija koje želimo da analiziramo?
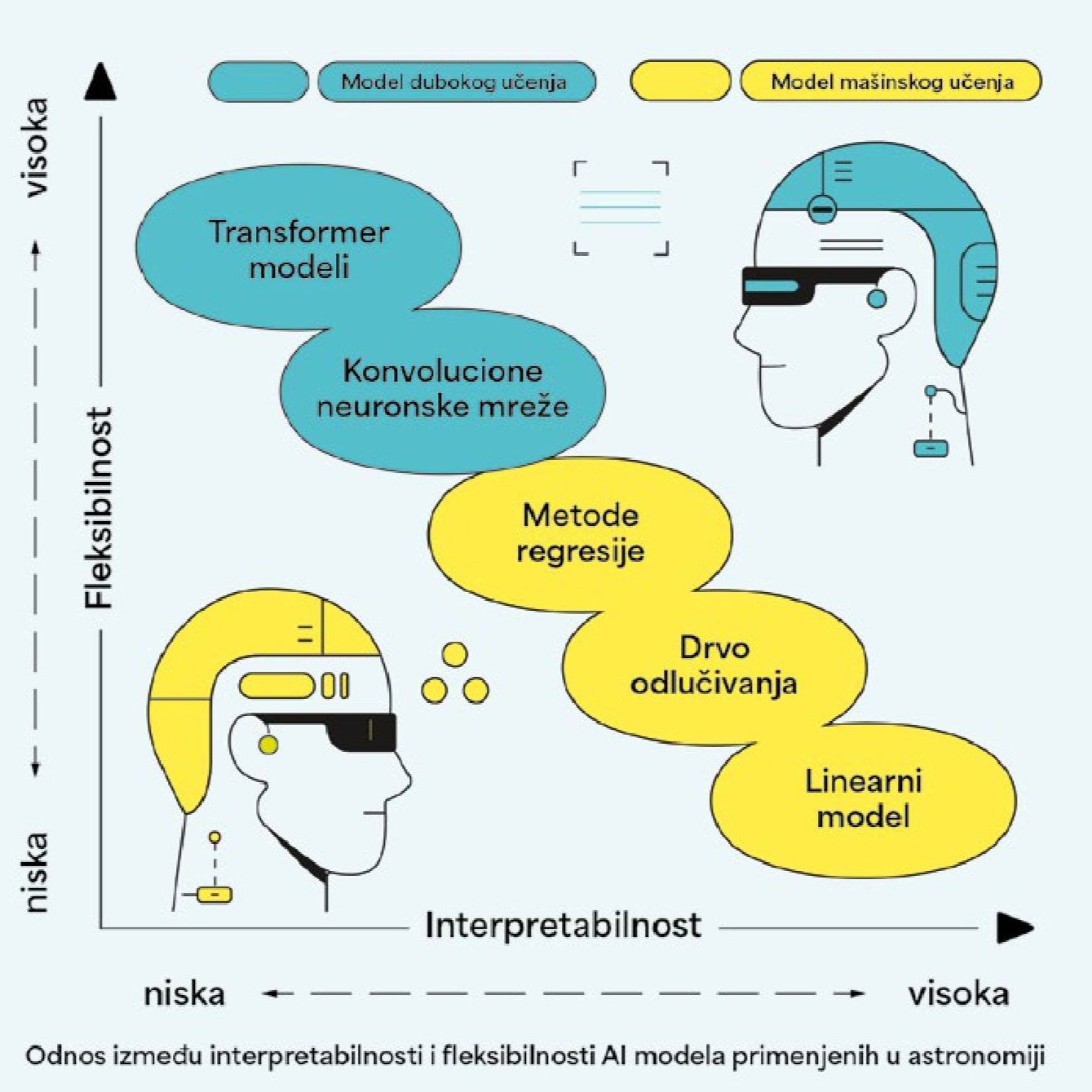
DVOBOJ TITANA: PRIMENA MAŠINSKOG I DUBOKOG UČENJA U ASTRONOMIJI
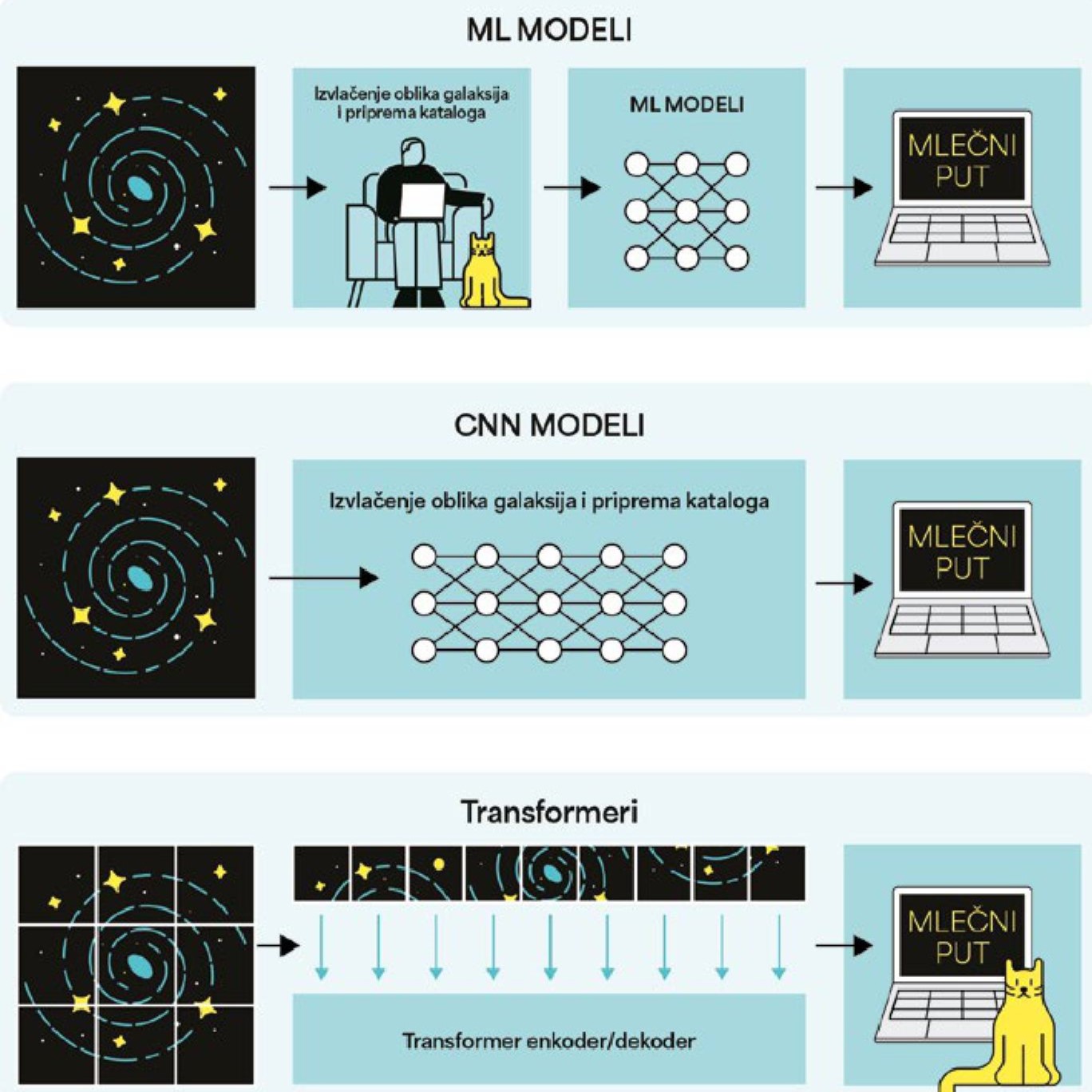
Prethodnih godina, naučnici su ovom problemu pristupali sa dva osnovna AI alata: modelima zasnovanim na mašinskom učenju (ML) i dubokom učenju (engl. deep learning). Obe metode iziskuju visokokvalitetne podatke značajne statistike. Mašinsko učenje je deo AI, a možemo ga definisati kao učenje iz podataka. Glavni cilj ML metoda je poboljšanje performansi klasifikacije podataka bez eksplicitnog programiranja. U svojoj osnovi, ML je skup raznih matematičkih tehnika koje tumače podatke upoređujući ih sa modelima koji opisuju njihovo ponašanje. Tu spadaju razni parametarski i neparametarski modeli, a najpoznatiji su drva odlučivanja, metode regresije, metode supervizirane i nesupervizirane klasifikacije, procene maksimalne verovatnoće i Bajesova analiza. U astronomiji često primenjujemo ML klasifikacije na velikim katalozima galaksija.
„Fitovanjem“ podataka, ML tehnike omogućavaju praćenje statističkih relacija u treniranim populacijama galaksija. Jedna od najčešće treniranih relacija je ona između mase i stope stvaranja zvezda u galaksijama, koja pomaže da galaksije klasifikujemo na aktivne (spiralne) i pasivne (eliptične). ML ima mogućnost ne samo da fituje (modelira) postojeće podatke, već pomaže i u njihovom interpretipristižućim ranju. Na primer, ML modeli mogu kvantitativno da porede više konkurentskih modela, na osnovu čega nam dalje mogu reći i da li (bar) jedan od njih može biti odbačen. Recimo, ukoliko bismo u katalog sa stotinu aktivnih spiralnih galaksija ubacili podatke za nekoliko pasivnih galaksija, ML modeli bi efikasno prepoznali „uljeza“, i sugerisali da te galaksije ne pripadaju osnovnom skupu.
Iako korisni, ML modeli u astronomiji imaju veliki nedostatak koji se ogleda u tome da kompjuter uči iz strukturiranih kataloga koje je čovek pažljivo pripremio. Da bismo ubrzali analizu i povećali mogućnost pronalaženja objekata koji su često skriveni našem oku, poslednjih godina sve su popularnije metode zasnovane na dubokom učenju i neuronskim mrežama, pre svega konvolucijske neuronske mreže (CNN). Ova metoda, motivisana strukturom čovekovog mozga, sačinjenom od interkonektovanih neurona, funkcioniše po principu „ja mogu da učim sama analizirajući konekcije koje uočavam na snimcima galaksija“. CNN je posebno zastupljen u analizi slika, i poslednjih godina je revolucionizovao klasifikovanje astronomskih objekata, na primer pomenute morfologije galaksija. Prvi astronomski naučni rad koji je primenio ovu metodu objavljen je 2015. godine, da bi nakon toga broj radova sa CNN-om eksponencijalno rastao sve do danas. CNN tretira slike kao strukturirane nizove piksela. Osnovna funkcija na koju se oslanja je konvolucija, ili pojednostavljeno – filterovanje. CNN primenjuje filter da bi pojačao ili smanjio svetlost određenog piksela na originalnoj slici, i bolje uočio obeležja koja su skrivena reprezentacija originalne slike, obično neobjašnjiva ljudskom oku. Fokus CNN metode je na maloj okolini najsvetlijeg piksela slike. Praktično govoreći, filteri pomažu da CNN identifikuje neke tipične osobine galaksija, poput delova kraka ili centralnog jezgra. To dalje pomaže algoritmu da generalizuje razvrstavanje na spiralne i eliptične galaksije.
Poznata veb-platforma za velike podatke Kaggle organizovala je takmičenje u tome koji AI metod najbolje razvrstava eliptične i spiralne galaksije na odabranom uzorku. Iako su i ML i CNN metode pokazale zavidan uspeh, CNN je odneo pobedu sa preciznošću od čak 90%. I ne samo to, već su CNN metode uspele da pronađu i neke retke vrste objekata (poput lokalnih patuljastih galaksija) pretražujući terabajte podataka. Treba reći da domen primenjivosti CNN metode nije ostao zatvoren samo za posmatračku astronomiju. Ona se uspešno koristi i u kompjuterskim simulacijama svemira, kada je potrebno na brz, statistički način povezati osnovne komponente simulacije – raspodelu tamne materije, i njihov odnos sa vidljivim materijom poput zvezda, gasa i prašine. Ipak, i pored ovih velikih rezultata, astronomi su i u CNN metodama otkrili značajne nedostatke.
CNN se fokusira na najsvetlije piksele, te zapostavlja tamnije predele na slikama koje mogu da „kriju“ vrlo važne fizičke podatke o svemirskim objektima. Takođe, CNN zahteva da ulazni podatak bude slika tačno određenih ivica, tako da filter koji se primenjuje bude skaliran sa veličinom te slike. Ovakav pristup limitira otkrivanje prostorno udaljenih objekata na slici, pogotovo ukoliko je jedan od njih svetliji a drugi tamniji. To je naročito veliki nedostatak za istraživanja svemira u kojem su česte interakcije dva i više objekata (galaksija, zvezda ili planeta sa satelitima).
TRANSFORMERS MODELI: NOVA REVOLUCIJA U ASTRONOMIJI?
Uzbuđenje istraživačke javnosti nije ni dostiglo pun vrhunac, kada se 2020. godine, naizgled niotkuda, pojavila nova AI arhitektura pod nazivom „transformeri“ (engl. transformer). Momentalno su skrenuli na sebe pažnju naučne javnosti jer su pokazali zavidne rezultate nadmašivši CNN ne samo u prepoznavanju objekata, već i u naprednijim izazovima poput detekcije slabo vidljivih galaksija u dalekom svemiru. Zabavnog imena, koje podseća na istoimenu kultnu animiranu seriju o robotima, vizualni transformer (VT) modeli su dizajnirani da efikasno rukuju tzv. sekvencionalnim podacima, a upravo to su spektri galaksija, krive sjaja zvezda ili slike slabo vidljivih difuznih galaksija čiju je veličinu teško izmeriti zbog niske površinske sjajnosti. Da bi nadomestili neke od nedostataka CNN metoda, VT modeli koriste specijalan koncept nazvan „metod pažnje“, koji kompjuteru pomaže da ulaznu sliku razdeli na segmente, i da identifikuje njen najbitniji deo, ne ograničavajući se samo na lokalne oblike ili najsvetlije piksele, kao što je to slučaj sa CNN-om.
U praksi, proces prepoznavanja oblika galaksija VT tehnikom izgleda ovako: ulazni snimak se segmentira u nekoliko manjih, koji se kasnije prevode u niz vektora kojima je dodeljena prostorna informacija (na pr. posmatrane koordinate). VT zatim sprovodi optimizaciju svojih mapa zasnovanih na „pažnji“, rekonstruišući čitavu sliku, a ne samo jedan njen deo.
Na ovaj način, VT modeli imaju prednost u pronalaženju realističnih fenomena u kosmosu koji se prostiru na velikim skalama, i čija sjajnost varira. Timovi astronoma se nadaju da će, primenjujući ovaj metod, uspeti da detektuju na milione svemirskih fenomena poput eksplozija supernova ili difuznih galaksija niske sjajnosti u nadolazećim velikim pretraživanjima neba teleskopima Vera Rubin ili Roman.
LEPOTA NESAVRŠENIH ALGORITAMA
Dok se za Kasparova govorilo kako je „poslednji stub odbrane čovečanstva pred robotom“, astronomska nauka je pokazala, za manje od decenije, da svaka nadolazeća AI arhitektura ima jasne nedostatke. Iako alati AI mogu izgledati inteligentni (i bukvalno se opisuju kao učenje!), oni su zapravo samo algoritmi napravljeni da prepoznaju određene obrasce i poboljšaju svoje rezultate sa povećanom količinom kvalitetnih ulaznih podataka. Stoga je prikladno da, umesto klasičnog zaključka, ovo Orbitiranje završimo malom listom najvažnijih nedostataka opisanih AI metoda koji čekaju na svoje poboljšavanje u godinama koje slede.
(1) Mnogi se pitaju da li AI može da otkrije nove fizičke zakone. Odgovor je „Ne“. AI je alat koji pomaže da unapredimo analizu i lakše prepoznamo nove veze među svemirskim telima.
(2) Sve AI metode iziskuju trening na velikim količinama podataka visoke kompletnosti i kvaliteta. Na primer, VT modeli potražuju desetak miliona slika da bi mogli da izvrše trening metodom „samostalnog mentorisanja“. Sa druge strane, ML modeli mogu da rade sa manjom statistikom, ali čovek je i dalje neophodan da bi „navigirao“ šta da se trenira i identifikuje.
(3) Metode bazirane na dubokom učenju funkcionišu po principu „zatvorene kutije“. U prevodu, jako je teško ljudskom logikom shvatiti na koji način je AI sproveo trening kojim izvršava zadatke.
(4) AI metode su ostvarile odlične performanse trenirajući se na slikama jednog određenog astronomskog instrumenta. Otvoreno pitanje je da li se sa istom preciznošću te metode mogu iskoristiti i za bilo koji drugi, heterogeniji set podataka? Galaksije u svemiru se snimaju instrumentima različite osetljivosti, a kosmički šum i prašina otežavaju detektabilnost objekata. Noviji radovi sugerišu da je AI metode moguće primeniti i na podatke koji nisu korišćeni za inicijalni „trening“, ali uz mnogo finih podešavanja. Predstoji, dakle, dosta posla da bi se dostigla željena efikasnost.
Dekada u kojoj živimo omogućila je sakupljanje podataka o stotinama miliona galaksija kroz više od 20 filtera. Bar još toliko galaksija tek treba da bude identifikovano i analizirano u nepreglednim snimcima i spektrima koje će na Zemlju slati budući teleskopi. Kvalitet AI modela zavisi od toga koliko je velik i kvalitetan set podataka koji mu serviramo za trening. Dok se to ne promeni (ako), otkriće veza među galaksijama će i u budućnosti biti delo čoveka.
Ovaj tekst objavljen je u 39. broju časopisa Elementi.
Darko Donevski je doktor nauka u oblasti kosmologije i astrofizike. Glavna oblast istraživanja mu je evolucija galaksija u ranom svemiru. Profesionalno je angažovan na institutima za astrofiziku u Trstu i Varšavi, na kojima vodi međunarodni projekat koji se bavi poreklom prašine u dalekim galaksijama. Doktorirao je na Univerzitetu Eks-Marsej u Francuskoj, a kao gostujući naučnik radio je na univerzitetima u Torontu, Lajdenu i Tuluzu. Pored istraživačkog rada, aktivno se bavi naučnom edukacijom i komunikacijom. Stalni je saradnik časopisa Elementi.